13. Natural Language Processing (NLP)#
It is an area of study that focuses on the processing of information contained in natural language.
13.1. Text Pre Processing#
Text segmentation and word tokenization
Language identification
Delete punctuation, digits, and words such as articles, determiners.
13.2. Tokenization#
Spacy Installation and Configuration#
!pip install --upgrade spacy
!pip install transformers
!python -m spacy download es_core_news_lg
import spacy
from spacy import displacy
nlp = spacy.load("es_core_news_lg")
Show code cell output
Requirement already satisfied: spacy in c:\python\python311\lib\site-packages (3.5.1)
Collecting spacy
Obtaining dependency information for spacy from https://files.pythonhosted.org/packages/90/f0/0133b684e18932c7bf4075d94819746cee2c0329f2569db526b0fa1df1df/spacy-3.7.2-cp311-cp311-win_amd64.whl.metadata
Downloading spacy-3.7.2-cp311-cp311-win_amd64.whl.metadata (26 kB)
Requirement already satisfied: spacy-legacy<3.1.0,>=3.0.11 in c:\python\python311\lib\site-packages (from spacy) (3.0.12)
Requirement already satisfied: spacy-loggers<2.0.0,>=1.0.0 in c:\python\python311\lib\site-packages (from spacy) (1.0.4)
Requirement already satisfied: murmurhash<1.1.0,>=0.28.0 in c:\python\python311\lib\site-packages (from spacy) (1.0.9)
Requirement already satisfied: cymem<2.1.0,>=2.0.2 in c:\python\python311\lib\site-packages (from spacy) (2.0.7)
Requirement already satisfied: preshed<3.1.0,>=3.0.2 in c:\python\python311\lib\site-packages (from spacy) (3.0.8)
Requirement already satisfied: thinc<8.3.0,>=8.1.8 in c:\python\python311\lib\site-packages (from spacy) (8.1.9)
Requirement already satisfied: wasabi<1.2.0,>=0.9.1 in c:\python\python311\lib\site-packages (from spacy) (1.1.1)
Requirement already satisfied: srsly<3.0.0,>=2.4.3 in c:\python\python311\lib\site-packages (from spacy) (2.4.6)
Requirement already satisfied: catalogue<2.1.0,>=2.0.6 in c:\python\python311\lib\site-packages (from spacy) (2.0.8)
Collecting weasel<0.4.0,>=0.1.0 (from spacy)
Obtaining dependency information for weasel<0.4.0,>=0.1.0 from https://files.pythonhosted.org/packages/d5/e5/b63b8e255d89ba4155972990d42523251d4d1368c4906c646597f63870e2/weasel-0.3.4-py3-none-any.whl.metadata
Downloading weasel-0.3.4-py3-none-any.whl.metadata (4.7 kB)
Requirement already satisfied: typer<0.10.0,>=0.3.0 in c:\python\python311\lib\site-packages (from spacy) (0.7.0)
Requirement already satisfied: smart-open<7.0.0,>=5.2.1 in c:\python\python311\lib\site-packages (from spacy) (6.3.0)
Requirement already satisfied: tqdm<5.0.0,>=4.38.0 in c:\python\python311\lib\site-packages (from spacy) (4.65.0)
Requirement already satisfied: requests<3.0.0,>=2.13.0 in c:\python\python311\lib\site-packages (from spacy) (2.28.2)
Requirement already satisfied: pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4 in c:\python\python311\lib\site-packages (from spacy) (1.10.7)
Requirement already satisfied: jinja2 in c:\python\python311\lib\site-packages (from spacy) (3.1.2)
Requirement already satisfied: setuptools in c:\python\python311\lib\site-packages (from spacy) (65.5.0)
Requirement already satisfied: packaging>=20.0 in c:\python\python311\lib\site-packages (from spacy) (23.0)
Requirement already satisfied: langcodes<4.0.0,>=3.2.0 in c:\python\python311\lib\site-packages (from spacy) (3.3.0)
Requirement already satisfied: numpy>=1.19.0 in c:\python\python311\lib\site-packages (from spacy) (1.23.5)
Requirement already satisfied: typing-extensions>=4.2.0 in c:\python\python311\lib\site-packages (from pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4->spacy) (4.5.0)
Requirement already satisfied: charset-normalizer<4,>=2 in c:\python\python311\lib\site-packages (from requests<3.0.0,>=2.13.0->spacy) (3.1.0)
Requirement already satisfied: idna<4,>=2.5 in c:\python\python311\lib\site-packages (from requests<3.0.0,>=2.13.0->spacy) (3.4)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in c:\python\python311\lib\site-packages (from requests<3.0.0,>=2.13.0->spacy) (1.26.15)
Requirement already satisfied: certifi>=2017.4.17 in c:\python\python311\lib\site-packages (from requests<3.0.0,>=2.13.0->spacy) (2022.12.7)
Requirement already satisfied: blis<0.8.0,>=0.7.8 in c:\python\python311\lib\site-packages (from thinc<8.3.0,>=8.1.8->spacy) (0.7.9)
Requirement already satisfied: confection<1.0.0,>=0.0.1 in c:\python\python311\lib\site-packages (from thinc<8.3.0,>=8.1.8->spacy) (0.0.4)
Requirement already satisfied: colorama in c:\python\python311\lib\site-packages (from tqdm<5.0.0,>=4.38.0->spacy) (0.4.6)
Requirement already satisfied: click<9.0.0,>=7.1.1 in c:\python\python311\lib\site-packages (from typer<0.10.0,>=0.3.0->spacy) (8.1.3)
Collecting cloudpathlib<0.17.0,>=0.7.0 (from weasel<0.4.0,>=0.1.0->spacy)
Obtaining dependency information for cloudpathlib<0.17.0,>=0.7.0 from https://files.pythonhosted.org/packages/0f/6e/45b57a7d4573d85d0b0a39d99673dc1f5eea9d92a1a4603b35e968fbf89a/cloudpathlib-0.16.0-py3-none-any.whl.metadata
Downloading cloudpathlib-0.16.0-py3-none-any.whl.metadata (14 kB)
Requirement already satisfied: MarkupSafe>=2.0 in c:\python\python311\lib\site-packages (from jinja2->spacy) (2.1.2)
Downloading spacy-3.7.2-cp311-cp311-win_amd64.whl (12.1 MB)
---------------------------------------- 0.0/12.1 MB ? eta -:--:--
- -------------------------------------- 0.3/12.1 MB 6.5 MB/s eta 0:00:02
-- ------------------------------------- 0.8/12.1 MB 8.1 MB/s eta 0:00:02
--- ------------------------------------ 1.1/12.1 MB 7.8 MB/s eta 0:00:02
----- ---------------------------------- 1.5/12.1 MB 8.9 MB/s eta 0:00:02
------- -------------------------------- 2.2/12.1 MB 9.2 MB/s eta 0:00:02
-------- ------------------------------- 2.6/12.1 MB 9.3 MB/s eta 0:00:02
---------- ----------------------------- 3.2/12.1 MB 9.6 MB/s eta 0:00:01
------------ --------------------------- 3.7/12.1 MB 9.9 MB/s eta 0:00:01
------------- -------------------------- 4.2/12.1 MB 9.9 MB/s eta 0:00:01
--------------- ------------------------ 4.7/12.1 MB 10.0 MB/s eta 0:00:01
----------------- ---------------------- 5.2/12.1 MB 10.1 MB/s eta 0:00:01
------------------ --------------------- 5.7/12.1 MB 10.1 MB/s eta 0:00:01
-------------------- ------------------- 6.1/12.1 MB 10.1 MB/s eta 0:00:01
---------------------- ----------------- 6.6/12.1 MB 10.1 MB/s eta 0:00:01
----------------------- ---------------- 7.2/12.1 MB 10.2 MB/s eta 0:00:01
------------------------- -------------- 7.6/12.1 MB 10.1 MB/s eta 0:00:01
-------------------------- ------------- 8.1/12.1 MB 10.1 MB/s eta 0:00:01
---------------------------- ----------- 8.6/12.1 MB 10.4 MB/s eta 0:00:01
------------------------------ --------- 9.1/12.1 MB 10.4 MB/s eta 0:00:01
------------------------------- -------- 9.5/12.1 MB 10.3 MB/s eta 0:00:01
-------------------------------- ------- 9.9/12.1 MB 10.2 MB/s eta 0:00:01
---------------------------------- ----- 10.4/12.1 MB 10.4 MB/s eta 0:00:01
------------------------------------ --- 10.9/12.1 MB 10.4 MB/s eta 0:00:01
------------------------------------- -- 11.4/12.1 MB 10.6 MB/s eta 0:00:01
--------------------------------------- 11.8/12.1 MB 10.6 MB/s eta 0:00:01
--------------------------------------- 12.1/12.1 MB 10.6 MB/s eta 0:00:01
---------------------------------------- 12.1/12.1 MB 10.2 MB/s eta 0:00:00
Downloading weasel-0.3.4-py3-none-any.whl (50 kB)
---------------------------------------- 0.0/50.1 kB ? eta -:--:--
---------------------------------------- 50.1/50.1 kB ? eta 0:00:00
Downloading cloudpathlib-0.16.0-py3-none-any.whl (45 kB)
---------------------------------------- 0.0/45.0 kB ? eta -:--:--
---------------------------------------- 45.0/45.0 kB ? eta 0:00:00
Installing collected packages: cloudpathlib, weasel, spacy
Attempting uninstall: spacy
Found existing installation: spacy 3.5.1
Uninstalling spacy-3.5.1:
Successfully uninstalled spacy-3.5.1
Successfully installed cloudpathlib-0.16.0 spacy-3.7.2 weasel-0.3.4
[notice] A new release of pip is available: 23.2.1 -> 23.3.2
[notice] To update, run: python.exe -m pip install --upgrade pip
Requirement already satisfied: transformers in c:\python\python311\lib\site-packages (4.27.4)
Requirement already satisfied: filelock in c:\python\python311\lib\site-packages (from transformers) (3.11.0)
Requirement already satisfied: huggingface-hub<1.0,>=0.11.0 in c:\python\python311\lib\site-packages (from transformers) (0.13.4)
Requirement already satisfied: numpy>=1.17 in c:\python\python311\lib\site-packages (from transformers) (1.23.5)
Requirement already satisfied: packaging>=20.0 in c:\python\python311\lib\site-packages (from transformers) (23.0)
Requirement already satisfied: pyyaml>=5.1 in c:\python\python311\lib\site-packages (from transformers) (6.0)
Requirement already satisfied: regex!=2019.12.17 in c:\python\python311\lib\site-packages (from transformers) (2023.3.23)
Requirement already satisfied: requests in c:\python\python311\lib\site-packages (from transformers) (2.28.2)
Requirement already satisfied: tokenizers!=0.11.3,<0.14,>=0.11.1 in c:\python\python311\lib\site-packages (from transformers) (0.13.3)
Requirement already satisfied: tqdm>=4.27 in c:\python\python311\lib\site-packages (from transformers) (4.65.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in c:\python\python311\lib\site-packages (from huggingface-hub<1.0,>=0.11.0->transformers) (4.5.0)
Requirement already satisfied: colorama in c:\python\python311\lib\site-packages (from tqdm>=4.27->transformers) (0.4.6)
Requirement already satisfied: charset-normalizer<4,>=2 in c:\python\python311\lib\site-packages (from requests->transformers) (3.1.0)
Requirement already satisfied: idna<4,>=2.5 in c:\python\python311\lib\site-packages (from requests->transformers) (3.4)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in c:\python\python311\lib\site-packages (from requests->transformers) (1.26.15)
Requirement already satisfied: certifi>=2017.4.17 in c:\python\python311\lib\site-packages (from requests->transformers) (2022.12.7)
[notice] A new release of pip is available: 23.2.1 -> 23.3.2
[notice] To update, run: python.exe -m pip install --upgrade pip
^CCollecting es-core-news-lg==3.7.0
Downloading https://github.com/explosion/spacy-models/releases/download/es_core_news_lg-3.7.0/es_core_news_lg-3.7.0-py3-none-any.whl (568.0 MB)
---------------------------------------- 0.0/568.0 MB ? eta -:--:--
---------------------------------------- 0.4/568.0 MB 8.1 MB/s eta 0:01:11
---------------------------------------- 0.8/568.0 MB 8.5 MB/s eta 0:01:07
---------------------------------------- 1.3/568.0 MB 9.3 MB/s eta 0:01:02
--------------------------------------- 1.7/568.0 MB 10.0 MB/s eta 0:00:57
--------------------------------------- 2.3/568.0 MB 10.4 MB/s eta 0:00:55
--------------------------------------- 2.8/568.0 MB 10.5 MB/s eta 0:00:54
--------------------------------------- 3.3/568.0 MB 10.5 MB/s eta 0:00:54
--------------------------------------- 3.8/568.0 MB 10.6 MB/s eta 0:00:54
--------------------------------------- 4.2/568.0 MB 10.4 MB/s eta 0:00:55
--------------------------------------- 4.7/568.0 MB 10.4 MB/s eta 0:00:54
--------------------------------------- 5.1/568.0 MB 10.3 MB/s eta 0:00:55
--------------------------------------- 5.6/568.0 MB 10.1 MB/s eta 0:00:56
--------------------------------------- 6.1/568.0 MB 10.2 MB/s eta 0:00:55
--------------------------------------- 6.5/568.0 MB 10.4 MB/s eta 0:00:55
--------------------------------------- 7.0/568.0 MB 10.2 MB/s eta 0:00:55
-------------------------------------- 7.4/568.0 MB 10.0 MB/s eta 0:00:56
-------------------------------------- 7.9/568.0 MB 10.0 MB/s eta 0:00:56
-------------------------------------- 8.3/568.0 MB 10.2 MB/s eta 0:00:56
-------------------------------------- 8.8/568.0 MB 10.2 MB/s eta 0:00:55
-------------------------------------- 9.3/568.0 MB 10.3 MB/s eta 0:00:55
-------------------------------------- 9.8/568.0 MB 10.2 MB/s eta 0:00:55
------------------------------------- 10.3/568.0 MB 10.4 MB/s eta 0:00:54
------------------------------------- 10.8/568.0 MB 10.4 MB/s eta 0:00:54
------------------------------------- 11.3/568.0 MB 10.4 MB/s eta 0:00:54
------------------------------------- 11.8/568.0 MB 10.4 MB/s eta 0:00:54
------------------------------------- 12.4/568.0 MB 10.6 MB/s eta 0:00:53
------------------------------------- 12.9/568.0 MB 10.4 MB/s eta 0:00:54
------------------------------------- 13.3/568.0 MB 10.4 MB/s eta 0:00:54
------------------------------------- 13.9/568.0 MB 10.4 MB/s eta 0:00:54
------------------------------------- 14.4/568.0 MB 10.4 MB/s eta 0:00:54
------------------------------------- 14.7/568.0 MB 10.4 MB/s eta 0:00:54
- ------------------------------------ 15.2/568.0 MB 10.4 MB/s eta 0:00:54
- ------------------------------------ 15.7/568.0 MB 10.4 MB/s eta 0:00:54
- ------------------------------------ 16.2/568.0 MB 10.4 MB/s eta 0:00:54
- ------------------------------------ 16.8/568.0 MB 10.6 MB/s eta 0:00:53
- ------------------------------------ 17.2/568.0 MB 10.6 MB/s eta 0:00:53
- ------------------------------------ 17.8/568.0 MB 10.7 MB/s eta 0:00:52
- ------------------------------------ 18.2/568.0 MB 10.7 MB/s eta 0:00:52
- ------------------------------------ 18.4/568.0 MB 10.7 MB/s eta 0:00:52
- ------------------------------------ 18.8/568.0 MB 10.4 MB/s eta 0:00:53
- ------------------------------------ 19.3/568.0 MB 10.4 MB/s eta 0:00:53
- ------------------------------------ 19.8/568.0 MB 10.2 MB/s eta 0:00:54
- ------------------------------------ 20.3/568.0 MB 10.4 MB/s eta 0:00:53
- ------------------------------------ 20.7/568.0 MB 10.4 MB/s eta 0:00:53
- ------------------------------------ 21.2/568.0 MB 10.2 MB/s eta 0:00:54
- ------------------------------------ 21.8/568.0 MB 10.4 MB/s eta 0:00:53
- ------------------------------------ 22.2/568.0 MB 10.2 MB/s eta 0:00:54
- ------------------------------------ 22.5/568.0 MB 10.1 MB/s eta 0:00:55
- ------------------------------------ 23.0/568.0 MB 10.1 MB/s eta 0:00:55
- ------------------------------------ 23.6/568.0 MB 10.2 MB/s eta 0:00:54
- ------------------------------------ 24.1/568.0 MB 10.2 MB/s eta 0:00:54
- ------------------------------------ 24.6/568.0 MB 10.1 MB/s eta 0:00:54
- ------------------------------------ 25.1/568.0 MB 10.2 MB/s eta 0:00:54
- ------------------------------------ 25.7/568.0 MB 10.2 MB/s eta 0:00:54
- ------------------------------------ 26.0/568.0 MB 10.1 MB/s eta 0:00:54
- ------------------------------------ 26.5/568.0 MB 10.2 MB/s eta 0:00:53
- ------------------------------------ 27.0/568.0 MB 10.2 MB/s eta 0:00:53
- ------------------------------------ 27.5/568.0 MB 10.1 MB/s eta 0:00:54
- ------------------------------------ 28.0/568.0 MB 10.2 MB/s eta 0:00:53
- ------------------------------------ 28.5/568.0 MB 10.1 MB/s eta 0:00:54
- ------------------------------------ 29.0/568.0 MB 10.7 MB/s eta 0:00:51
- ------------------------------------ 29.6/568.0 MB 10.7 MB/s eta 0:00:51
-- ----------------------------------- 30.1/568.0 MB 10.7 MB/s eta 0:00:51
-- ----------------------------------- 30.6/568.0 MB 10.7 MB/s eta 0:00:51
-- ----------------------------------- 31.1/568.0 MB 10.7 MB/s eta 0:00:51
-- ----------------------------------- 31.7/568.0 MB 10.7 MB/s eta 0:00:50
-- ----------------------------------- 32.2/568.0 MB 10.7 MB/s eta 0:00:50
-- ----------------------------------- 32.6/568.0 MB 10.9 MB/s eta 0:00:50
-- ----------------------------------- 33.2/568.0 MB 11.1 MB/s eta 0:00:49
-- ----------------------------------- 33.7/568.0 MB 11.1 MB/s eta 0:00:49
-- ----------------------------------- 34.2/568.0 MB 10.9 MB/s eta 0:00:49
-- ----------------------------------- 34.6/568.0 MB 10.9 MB/s eta 0:00:49
-- ----------------------------------- 35.1/568.0 MB 10.9 MB/s eta 0:00:49
-- ----------------------------------- 35.4/568.0 MB 10.7 MB/s eta 0:00:50
-- ----------------------------------- 35.9/568.0 MB 10.7 MB/s eta 0:00:50
-- ----------------------------------- 36.3/568.0 MB 10.6 MB/s eta 0:00:51
-- ----------------------------------- 36.9/568.0 MB 10.7 MB/s eta 0:00:50
-- ----------------------------------- 37.3/568.0 MB 10.6 MB/s eta 0:00:51
-- ----------------------------------- 37.7/568.0 MB 10.4 MB/s eta 0:00:52
-- ----------------------------------- 38.1/568.0 MB 10.4 MB/s eta 0:00:51
-- ----------------------------------- 38.7/568.0 MB 10.4 MB/s eta 0:00:51
-- ----------------------------------- 39.1/568.0 MB 10.4 MB/s eta 0:00:51
-- ----------------------------------- 39.7/568.0 MB 10.4 MB/s eta 0:00:51
-- ----------------------------------- 40.2/568.0 MB 10.2 MB/s eta 0:00:52
-- ----------------------------------- 40.7/568.0 MB 10.4 MB/s eta 0:00:51
-- ----------------------------------- 41.2/568.0 MB 10.4 MB/s eta 0:00:51
-- ----------------------------------- 41.7/568.0 MB 10.2 MB/s eta 0:00:52
-- ----------------------------------- 42.2/568.0 MB 10.2 MB/s eta 0:00:52
-- ----------------------------------- 42.7/568.0 MB 10.2 MB/s eta 0:00:52
-- ----------------------------------- 43.2/568.0 MB 10.2 MB/s eta 0:00:52
-- ----------------------------------- 43.7/568.0 MB 10.2 MB/s eta 0:00:52
-- ----------------------------------- 44.2/568.0 MB 10.2 MB/s eta 0:00:52
-- ----------------------------------- 44.7/568.0 MB 10.2 MB/s eta 0:00:52
--- ---------------------------------- 45.2/568.0 MB 10.2 MB/s eta 0:00:52
--- ---------------------------------- 45.7/568.0 MB 10.4 MB/s eta 0:00:51
--- ---------------------------------- 46.3/568.0 MB 10.6 MB/s eta 0:00:50
--- ---------------------------------- 46.8/568.0 MB 10.6 MB/s eta 0:00:50
--- ---------------------------------- 47.3/568.0 MB 10.7 MB/s eta 0:00:49
--- ---------------------------------- 47.8/568.0 MB 10.7 MB/s eta 0:00:49
--- ---------------------------------- 48.3/568.0 MB 10.9 MB/s eta 0:00:48
--- ---------------------------------- 48.9/568.0 MB 10.9 MB/s eta 0:00:48
--- ---------------------------------- 49.3/568.0 MB 10.7 MB/s eta 0:00:49
--- ---------------------------------- 49.8/568.0 MB 10.7 MB/s eta 0:00:49
--- ---------------------------------- 50.2/568.0 MB 10.7 MB/s eta 0:00:49
--- ---------------------------------- 50.7/568.0 MB 10.7 MB/s eta 0:00:49
--- ---------------------------------- 51.2/568.0 MB 10.7 MB/s eta 0:00:49
--- ---------------------------------- 51.8/568.0 MB 10.7 MB/s eta 0:00:49
--- ---------------------------------- 52.3/568.0 MB 10.7 MB/s eta 0:00:49
--- ---------------------------------- 52.8/568.0 MB 10.9 MB/s eta 0:00:48
--- ---------------------------------- 53.3/568.0 MB 10.7 MB/s eta 0:00:48
--- ---------------------------------- 53.8/568.0 MB 10.7 MB/s eta 0:00:48
--- ---------------------------------- 54.3/568.0 MB 10.7 MB/s eta 0:00:48
--- ---------------------------------- 54.8/568.0 MB 10.7 MB/s eta 0:00:48
--- ---------------------------------- 55.3/568.0 MB 10.7 MB/s eta 0:00:48
--- ---------------------------------- 55.8/568.0 MB 10.7 MB/s eta 0:00:48
--- ---------------------------------- 56.4/568.0 MB 10.7 MB/s eta 0:00:48
--- ---------------------------------- 56.9/568.0 MB 10.9 MB/s eta 0:00:47
--- ---------------------------------- 57.3/568.0 MB 10.7 MB/s eta 0:00:48
--- ---------------------------------- 57.8/568.0 MB 10.7 MB/s eta 0:00:48
--- ---------------------------------- 58.4/568.0 MB 10.7 MB/s eta 0:00:48
--- ---------------------------------- 58.9/568.0 MB 10.7 MB/s eta 0:00:48
--- ---------------------------------- 59.4/568.0 MB 10.9 MB/s eta 0:00:47
---- --------------------------------- 59.9/568.0 MB 10.9 MB/s eta 0:00:47
---- --------------------------------- 60.2/568.0 MB 10.7 MB/s eta 0:00:48
---- --------------------------------- 60.7/568.0 MB 10.9 MB/s eta 0:00:47
---- --------------------------------- 61.1/568.0 MB 10.7 MB/s eta 0:00:48
---- --------------------------------- 61.6/568.0 MB 10.7 MB/s eta 0:00:48
---- --------------------------------- 62.2/568.0 MB 10.7 MB/s eta 0:00:48
---- --------------------------------- 62.6/568.0 MB 10.6 MB/s eta 0:00:48
---- --------------------------------- 63.2/568.0 MB 10.6 MB/s eta 0:00:48
---- --------------------------------- 63.6/568.0 MB 10.6 MB/s eta 0:00:48
---- --------------------------------- 64.2/568.0 MB 10.7 MB/s eta 0:00:47
---- --------------------------------- 64.7/568.0 MB 10.7 MB/s eta 0:00:47
---- --------------------------------- 65.2/568.0 MB 10.7 MB/s eta 0:00:47
---- --------------------------------- 65.6/568.0 MB 10.6 MB/s eta 0:00:48
---- --------------------------------- 66.2/568.0 MB 10.6 MB/s eta 0:00:48
---- --------------------------------- 66.7/568.0 MB 10.6 MB/s eta 0:00:48
---- --------------------------------- 67.3/568.0 MB 10.6 MB/s eta 0:00:48
---- --------------------------------- 67.8/568.0 MB 10.7 MB/s eta 0:00:47
---- --------------------------------- 68.3/568.0 MB 10.7 MB/s eta 0:00:47
---- --------------------------------- 68.9/568.0 MB 10.7 MB/s eta 0:00:47
---- --------------------------------- 69.2/568.0 MB 10.6 MB/s eta 0:00:48
---- --------------------------------- 69.7/568.0 MB 10.6 MB/s eta 0:00:48
---- --------------------------------- 70.2/568.0 MB 10.7 MB/s eta 0:00:47
---- --------------------------------- 70.7/568.0 MB 10.9 MB/s eta 0:00:46
---- --------------------------------- 71.2/568.0 MB 10.9 MB/s eta 0:00:46
---- --------------------------------- 71.7/568.0 MB 10.7 MB/s eta 0:00:47
---- --------------------------------- 72.2/568.0 MB 10.7 MB/s eta 0:00:47
---- --------------------------------- 72.7/568.0 MB 10.7 MB/s eta 0:00:47
---- --------------------------------- 73.1/568.0 MB 10.7 MB/s eta 0:00:47
---- --------------------------------- 73.6/568.0 MB 10.6 MB/s eta 0:00:47
---- --------------------------------- 74.1/568.0 MB 10.6 MB/s eta 0:00:47
---- --------------------------------- 74.6/568.0 MB 10.6 MB/s eta 0:00:47
----- -------------------------------- 75.1/568.0 MB 10.6 MB/s eta 0:00:47
----- -------------------------------- 75.6/568.0 MB 10.7 MB/s eta 0:00:46
----- -------------------------------- 76.1/568.0 MB 10.7 MB/s eta 0:00:46
----- -------------------------------- 76.6/568.0 MB 10.6 MB/s eta 0:00:47
----- -------------------------------- 76.8/568.0 MB 10.2 MB/s eta 0:00:49
----- -------------------------------- 77.4/568.0 MB 10.2 MB/s eta 0:00:48
----- -------------------------------- 77.8/568.0 MB 10.2 MB/s eta 0:00:48
----- -------------------------------- 78.3/568.0 MB 10.2 MB/s eta 0:00:48
----- -------------------------------- 78.8/568.0 MB 10.2 MB/s eta 0:00:48
----- -------------------------------- 79.4/568.0 MB 10.2 MB/s eta 0:00:48
----- -------------------------------- 79.8/568.0 MB 10.2 MB/s eta 0:00:48
----- -------------------------------- 80.3/568.0 MB 10.2 MB/s eta 0:00:48
----- -------------------------------- 80.8/568.0 MB 10.2 MB/s eta 0:00:48
----- -------------------------------- 81.4/568.0 MB 10.4 MB/s eta 0:00:47
----- -------------------------------- 81.9/568.0 MB 10.4 MB/s eta 0:00:47
----- -------------------------------- 82.4/568.0 MB 10.4 MB/s eta 0:00:47
----- -------------------------------- 83.0/568.0 MB 10.6 MB/s eta 0:00:46
----- -------------------------------- 83.5/568.0 MB 10.6 MB/s eta 0:00:46
----- -------------------------------- 84.0/568.0 MB 10.6 MB/s eta 0:00:46
----- -------------------------------- 84.4/568.0 MB 10.6 MB/s eta 0:00:46
----- -------------------------------- 85.0/568.0 MB 10.6 MB/s eta 0:00:46
----- -------------------------------- 85.3/568.0 MB 10.6 MB/s eta 0:00:46
----- -------------------------------- 85.7/568.0 MB 10.2 MB/s eta 0:00:48
----- -------------------------------- 86.2/568.0 MB 10.2 MB/s eta 0:00:48
----- -------------------------------- 86.6/568.0 MB 10.1 MB/s eta 0:00:48
----- -------------------------------- 87.1/568.0 MB 10.4 MB/s eta 0:00:47
----- -------------------------------- 87.4/568.0 MB 10.2 MB/s eta 0:00:47
------ -------------------------------- 87.7/568.0 MB 9.9 MB/s eta 0:00:49
----- -------------------------------- 88.2/568.0 MB 10.2 MB/s eta 0:00:47
----- -------------------------------- 88.8/568.0 MB 10.1 MB/s eta 0:00:48
----- -------------------------------- 89.2/568.0 MB 10.1 MB/s eta 0:00:48
------ ------------------------------- 89.7/568.0 MB 10.2 MB/s eta 0:00:47
------ ------------------------------- 90.2/568.0 MB 10.2 MB/s eta 0:00:47
------ ------------------------------- 90.7/568.0 MB 10.2 MB/s eta 0:00:47
------ ------------------------------- 91.2/568.0 MB 10.1 MB/s eta 0:00:48
------ ------------------------------- 91.6/568.0 MB 10.1 MB/s eta 0:00:48
------ -------------------------------- 91.9/568.0 MB 9.9 MB/s eta 0:00:48
------ -------------------------------- 92.4/568.0 MB 9.8 MB/s eta 0:00:49
------ -------------------------------- 92.8/568.0 MB 9.8 MB/s eta 0:00:49
------ -------------------------------- 93.4/568.0 MB 9.6 MB/s eta 0:00:50
------ -------------------------------- 93.9/568.0 MB 9.8 MB/s eta 0:00:49
------ -------------------------------- 94.3/568.0 MB 9.8 MB/s eta 0:00:49
------ -------------------------------- 94.7/568.0 MB 9.6 MB/s eta 0:00:50
------ -------------------------------- 95.1/568.0 MB 9.5 MB/s eta 0:00:50
------ -------------------------------- 95.6/568.0 MB 9.6 MB/s eta 0:00:50
------ -------------------------------- 96.2/568.0 MB 9.9 MB/s eta 0:00:48
------ ------------------------------- 96.6/568.0 MB 10.1 MB/s eta 0:00:47
------ ------------------------------- 97.2/568.0 MB 10.2 MB/s eta 0:00:47
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
Cell In[1], line 6
4 import spacy
5 from spacy import displacy
----> 6 nlp = spacy.load("es_core_news_lg")
File C:\Python\Python311\Lib\site-packages\spacy\__init__.py:51, in load(name, vocab, disable, enable, exclude, config)
27 def load(
28 name: Union[str, Path],
29 *,
(...)
34 config: Union[Dict[str, Any], Config] = util.SimpleFrozenDict(),
35 ) -> Language:
36 """Load a spaCy model from an installed package or a local path.
37
38 name (str): Package name or model path.
(...)
49 RETURNS (Language): The loaded nlp object.
50 """
---> 51 return util.load_model(
52 name,
53 vocab=vocab,
54 disable=disable,
55 enable=enable,
56 exclude=exclude,
57 config=config,
58 )
File C:\Python\Python311\Lib\site-packages\spacy\util.py:472, in load_model(name, vocab, disable, enable, exclude, config)
470 if name in OLD_MODEL_SHORTCUTS:
471 raise IOError(Errors.E941.format(name=name, full=OLD_MODEL_SHORTCUTS[name])) # type: ignore[index]
--> 472 raise IOError(Errors.E050.format(name=name))
OSError: [E050] Can't find model 'es_core_news_lg'. It doesn't seem to be a Python package or a valid path to a data directory.
text="""El presidente de la República Pedro Castillo anunció la creación del denominado \
Servicio Civil Agrario - Secigra, con la finalidad de que “miles de jóvenes universitarios \
recién egresados” vayan al campo para brindar apoyo técnico “a nuestros agricultores \
y agricultoras”. “Tenemos en preparación un programa de servicio civil agrario, al que llamamos \
Secigra-Agrario, por lo cual miles de jóvenes universitarios, recién egresados, saldrán al \
campo a apoyar técnicamente a nuestro agricultores”, expresó."""
text
'El presidente de la República Pedro Castillo anunció la creación del denominado Servicio Civil Agrario - Secigra, con la finalidad de que “miles de jóvenes universitarios recién egresados” vayan al campo para brindar apoyo técnico “a nuestros agricultores y agricultoras”. “Tenemos en preparación un programa de servicio civil agrario, al que llamamos Secigra-Agrario, por lo cual miles de jóvenes universitarios, recién egresados, saldrán al campo a apoyar técnicamente a nuestro agricultores”, expresó.'
Sentence tokenization#
doc = nlp(text)
for idx,sent in enumerate(doc.sents):
print(f'sentencia {idx+1}: ', sent)
print()
sentencia 1: El presidente de la República Pedro Castillo anunció la creación del denominado Servicio Civil Agrario - Secigra, con la finalidad de que “miles de jóvenes universitarios recién egresados” vayan al campo para brindar apoyo técnico “a nuestros agricultores y agricultoras”.
sentencia 2: “Tenemos en preparación un programa de servicio civil agrario, al que llamamos Secigra-Agrario, por lo cual miles de jóvenes universitarios, recién egresados, saldrán al campo a apoyar técnicamente a nuestro agricultores”, expresó.
1) Whitespace tokenizer#
print(text.split(' '))
['El', 'presidente', 'de', 'la', 'República', 'Pedro', 'Castillo', 'anunció', 'la', 'creación', 'del', 'denominado', 'Servicio', 'Civil', 'Agrario', '-', 'Secigra,', 'con', 'la', 'finalidad', 'de', 'que', '“miles', 'de', 'jóvenes', 'universitarios', 'recién', 'egresados”', 'vayan', 'al', 'campo', 'para', 'brindar', 'apoyo', 'técnico', '“a', 'nuestros', 'agricultores', 'y', 'agricultoras”.', '“Tenemos', 'en', 'preparación', 'un', 'programa', 'de', 'servicio', 'civil', 'agrario,', 'al', 'que', 'llamamos', 'Secigra-Agrario,', 'por', 'lo', 'cual', 'miles', 'de', 'jóvenes', 'universitarios,', 'recién', 'egresados,', 'saldrán', 'al', 'campo', 'a', 'apoyar', 'técnicamente', 'a', 'nuestro', 'agricultores”,', 'expresó.']
2) Word tokenization#
from spacy.tokenizer import Tokenizer
from spacy.lang.es import Spanish
nlp = Spanish()
tokens = nlp.tokenizer(text)
print(list(tokens))
[El, presidente, de, la, República, Pedro, Castillo, anunció, la, creación, del, denominado, Servicio, Civil, Agrario, -, Secigra, ,, con, la, finalidad, de, que, “, miles, de, jóvenes, universitarios, recién, egresados, ”, vayan, al, campo, para, brindar, apoyo, técnico, “, a, nuestros, agricultores, y, agricultoras, ”, ., “, Tenemos, en, preparación, un, programa, de, servicio, civil, agrario, ,, al, que, llamamos, Secigra-Agrario, ,, por, lo, cual, miles, de, jóvenes, universitarios, ,, recién, egresados, ,, saldrán, al, campo, a, apoyar, técnicamente, a, nuestro, agricultores, ”, ,, expresó, .]
3) Subword tokenization#
from transformers import BertTokenizer
#tz = BertTokenizer.from_pretrained("bert-base-cased")
tz = BertTokenizer.from_pretrained("bert-base-multilingual-cased")
tz.tokenize(text)
['El',
'presidente',
'de',
'la',
'República',
'Pedro',
'Castillo',
'anunció',
'la',
'creación',
'del',
'denominado',
'Servicio',
'Civil',
'A',
'##gra',
'##rio',
'-',
'Sec',
'##ig',
'##ra',
',',
'con',
'la',
'finali',
'##dad',
'de',
'que',
'[UNK]',
'miles',
'de',
'jóvenes',
'universitario',
'##s',
'recién',
'e',
'##gres',
'##ados',
'[UNK]',
'va',
'##yan',
'al',
'campo',
'para',
'br',
'##inda',
'##r',
'apoyo',
'técnico',
'[UNK]',
'a',
'nuestros',
'ag',
'##ricu',
'##lto',
'##res',
'y',
'ag',
'##ricu',
'##lto',
'##ras',
'[UNK]',
'.',
'[UNK]',
'Ten',
'##emos',
'en',
'preparación',
'un',
'programa',
'de',
'servicio',
'civil',
'ag',
'##rar',
'##io',
',',
'al',
'que',
'llama',
'##mos',
'Sec',
'##ig',
'##ra',
'-',
'A',
'##gra',
'##rio',
',',
'por',
'lo',
'cual',
'miles',
'de',
'jóvenes',
'universitario',
'##s',
',',
'recién',
'e',
'##gres',
'##ados',
',',
'sal',
'##dr',
'##án',
'al',
'campo',
'a',
'apo',
'##yar',
'técnica',
'##mente',
'a',
'nuestro',
'ag',
'##ricu',
'##lto',
'##res',
'[UNK]',
',',
'ex',
'##pres',
'##ó',
'.']
13.3. Feature Encoding - Vectorization#
Sentences can be generated as vectors. Then, each word now represents a vector, but is characterized by its context in the sentences it is found in. In this way, we find similarities between words using vectors.
!pip install gensim==3.8.0
!pip install pyemd
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: gensim==3.8.0 in /usr/local/lib/python3.9/dist-packages (3.8.0)
Requirement already satisfied: smart-open>=1.7.0 in /usr/local/lib/python3.9/dist-packages (from gensim==3.8.0) (6.3.0)
Requirement already satisfied: six>=1.5.0 in /usr/local/lib/python3.9/dist-packages (from gensim==3.8.0) (1.16.0)
Requirement already satisfied: scipy>=0.18.1 in /usr/local/lib/python3.9/dist-packages (from gensim==3.8.0) (1.10.1)
Requirement already satisfied: numpy>=1.11.3 in /usr/local/lib/python3.9/dist-packages (from gensim==3.8.0) (1.22.4)
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting pyemd
Downloading pyemd-1.0.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (675 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 675.0/675.0 KB 18.3 MB/s eta 0:00:00
?25hRequirement already satisfied: numpy>=1.9.0 in /usr/local/lib/python3.9/dist-packages (from pyemd) (1.22.4)
Installing collected packages: pyemd
Successfully installed pyemd-1.0.0
!pip install stanza
%matplotlib inline
import glob
import numpy as np
import matplotlib.pyplot as plt
import nltk
from nltk.corpus import stopwords
import csv
import gensim
import pandas as pd
from itertools import groupby
from gensim.similarities import WmdSimilarity
from gensim.models import Word2Vec
nltk.download('punkt')
nltk.download('stopwords')
stop_words = stopwords.words('spanish')
import stanza
import re
stanza.download('es')
print(stop_words)
nlp = stanza.Pipeline(processors='tokenize',lang='es',use_gpu=True)
Show code cell output
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: stanza in /usr/local/lib/python3.9/dist-packages (1.5.0)
Requirement already satisfied: emoji in /usr/local/lib/python3.9/dist-packages (from stanza) (2.2.0)
Requirement already satisfied: numpy in /usr/local/lib/python3.9/dist-packages (from stanza) (1.22.4)
Requirement already satisfied: tqdm in /usr/local/lib/python3.9/dist-packages (from stanza) (4.65.0)
Requirement already satisfied: protobuf in /usr/local/lib/python3.9/dist-packages (from stanza) (3.20.3)
Requirement already satisfied: torch>=1.3.0 in /usr/local/lib/python3.9/dist-packages (from stanza) (1.13.1+cu116)
Requirement already satisfied: requests in /usr/local/lib/python3.9/dist-packages (from stanza) (2.27.1)
Requirement already satisfied: six in /usr/local/lib/python3.9/dist-packages (from stanza) (1.16.0)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.9/dist-packages (from torch>=1.3.0->stanza) (4.5.0)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.9/dist-packages (from requests->stanza) (2.0.12)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.9/dist-packages (from requests->stanza) (1.26.15)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.9/dist-packages (from requests->stanza) (2022.12.7)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.9/dist-packages (from requests->stanza) (3.4)
[nltk_data] Downloading package punkt to /root/nltk_data...
[nltk_data] Package punkt is already up-to-date!
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!
INFO:stanza:Downloading default packages for language: es (Spanish) ...
INFO:stanza:File exists: /root/stanza_resources/es/default.zip
INFO:stanza:Finished downloading models and saved to /root/stanza_resources.
INFO:stanza:Checking for updates to resources.json in case models have been updated. Note: this behavior can be turned off with download_method=None or download_method=DownloadMethod.REUSE_RESOURCES
['de', 'la', 'que', 'el', 'en', 'y', 'a', 'los', 'del', 'se', 'las', 'por', 'un', 'para', 'con', 'no', 'una', 'su', 'al', 'lo', 'como', 'más', 'pero', 'sus', 'le', 'ya', 'o', 'este', 'sí', 'porque', 'esta', 'entre', 'cuando', 'muy', 'sin', 'sobre', 'también', 'me', 'hasta', 'hay', 'donde', 'quien', 'desde', 'todo', 'nos', 'durante', 'todos', 'uno', 'les', 'ni', 'contra', 'otros', 'ese', 'eso', 'ante', 'ellos', 'e', 'esto', 'mí', 'antes', 'algunos', 'qué', 'unos', 'yo', 'otro', 'otras', 'otra', 'él', 'tanto', 'esa', 'estos', 'mucho', 'quienes', 'nada', 'muchos', 'cual', 'poco', 'ella', 'estar', 'estas', 'algunas', 'algo', 'nosotros', 'mi', 'mis', 'tú', 'te', 'ti', 'tu', 'tus', 'ellas', 'nosotras', 'vosotros', 'vosotras', 'os', 'mío', 'mía', 'míos', 'mías', 'tuyo', 'tuya', 'tuyos', 'tuyas', 'suyo', 'suya', 'suyos', 'suyas', 'nuestro', 'nuestra', 'nuestros', 'nuestras', 'vuestro', 'vuestra', 'vuestros', 'vuestras', 'esos', 'esas', 'estoy', 'estás', 'está', 'estamos', 'estáis', 'están', 'esté', 'estés', 'estemos', 'estéis', 'estén', 'estaré', 'estarás', 'estará', 'estaremos', 'estaréis', 'estarán', 'estaría', 'estarías', 'estaríamos', 'estaríais', 'estarían', 'estaba', 'estabas', 'estábamos', 'estabais', 'estaban', 'estuve', 'estuviste', 'estuvo', 'estuvimos', 'estuvisteis', 'estuvieron', 'estuviera', 'estuvieras', 'estuviéramos', 'estuvierais', 'estuvieran', 'estuviese', 'estuvieses', 'estuviésemos', 'estuvieseis', 'estuviesen', 'estando', 'estado', 'estada', 'estados', 'estadas', 'estad', 'he', 'has', 'ha', 'hemos', 'habéis', 'han', 'haya', 'hayas', 'hayamos', 'hayáis', 'hayan', 'habré', 'habrás', 'habrá', 'habremos', 'habréis', 'habrán', 'habría', 'habrías', 'habríamos', 'habríais', 'habrían', 'había', 'habías', 'habíamos', 'habíais', 'habían', 'hube', 'hubiste', 'hubo', 'hubimos', 'hubisteis', 'hubieron', 'hubiera', 'hubieras', 'hubiéramos', 'hubierais', 'hubieran', 'hubiese', 'hubieses', 'hubiésemos', 'hubieseis', 'hubiesen', 'habiendo', 'habido', 'habida', 'habidos', 'habidas', 'soy', 'eres', 'es', 'somos', 'sois', 'son', 'sea', 'seas', 'seamos', 'seáis', 'sean', 'seré', 'serás', 'será', 'seremos', 'seréis', 'serán', 'sería', 'serías', 'seríamos', 'seríais', 'serían', 'era', 'eras', 'éramos', 'erais', 'eran', 'fui', 'fuiste', 'fue', 'fuimos', 'fuisteis', 'fueron', 'fuera', 'fueras', 'fuéramos', 'fuerais', 'fueran', 'fuese', 'fueses', 'fuésemos', 'fueseis', 'fuesen', 'sintiendo', 'sentido', 'sentida', 'sentidos', 'sentidas', 'siente', 'sentid', 'tengo', 'tienes', 'tiene', 'tenemos', 'tenéis', 'tienen', 'tenga', 'tengas', 'tengamos', 'tengáis', 'tengan', 'tendré', 'tendrás', 'tendrá', 'tendremos', 'tendréis', 'tendrán', 'tendría', 'tendrías', 'tendríamos', 'tendríais', 'tendrían', 'tenía', 'tenías', 'teníamos', 'teníais', 'tenían', 'tuve', 'tuviste', 'tuvo', 'tuvimos', 'tuvisteis', 'tuvieron', 'tuviera', 'tuvieras', 'tuviéramos', 'tuvierais', 'tuvieran', 'tuviese', 'tuvieses', 'tuviésemos', 'tuvieseis', 'tuviesen', 'teniendo', 'tenido', 'tenida', 'tenidos', 'tenidas', 'tened']
WARNING:stanza:Language es package default expects mwt, which has been added
INFO:stanza:Loading these models for language: es (Spanish):
=======================
| Processor | Package |
-----------------------
| tokenize | ancora |
| mwt | ancora |
=======================
INFO:stanza:Using device: cuda
INFO:stanza:Loading: tokenize
INFO:stanza:Loading: mwt
INFO:stanza:Done loading processors!
# Quitamos los stop words
# articulos, adverbios
def preprocessing(words):
clean_sentence=[]
for word in words:
word = word.lower()
if (word not in stop_words) and word.isalpha():
clean_sentence.append(word)
return clean_sentence
# Tomamos oraciones
# tokenizamos
# Generamos listas de oraciones limpias
def preprocessing_sentences(all_news):
all_sentences = []
raw_sentences=[]
for new in tqdm(all_news):
doc = nlp(new)
for sentence in doc.sentences:
words = [word.text for word in sentence.words]
if len(words)>5:
clean_sentence=preprocessing(words)
all_sentences.append(clean_sentence)
raw_sentences.append(words)
return all_sentences,raw_sentences
# Importar base de datos
df = pd.read_csv( r"https://www.dropbox.com/s/fjiwa26yjobrtfz/sample_news.csv?dl=1")
# Reemplazar np.nan
# por strings vacios
df.body = df.body.replace( np.nan, "")
# String de oraciones
all_news = df.body.str.strip()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-13-94bc084f11b1> in <cell line: 5>()
3 # Reemplazar np.nan
4 # por strings vacios
----> 5 df.body = df.body.replace( np.nan, "")
6 # String de oraciones
7 all_news = df.body.str.strip()
NameError: name 'np' is not defined
# Procesamiento de las oraciones
from tqdm import tqdm
sentences,raw_sentences = preprocessing_sentences(all_news)
len(sentences)
lens = [len(sentence) for sentence in sentences]
avg_len = sum(lens) / float(len(lens))
100%|██████████| 300/300 [00:20<00:00, 14.43it/s]
# Plot de Longitud de las oraciones
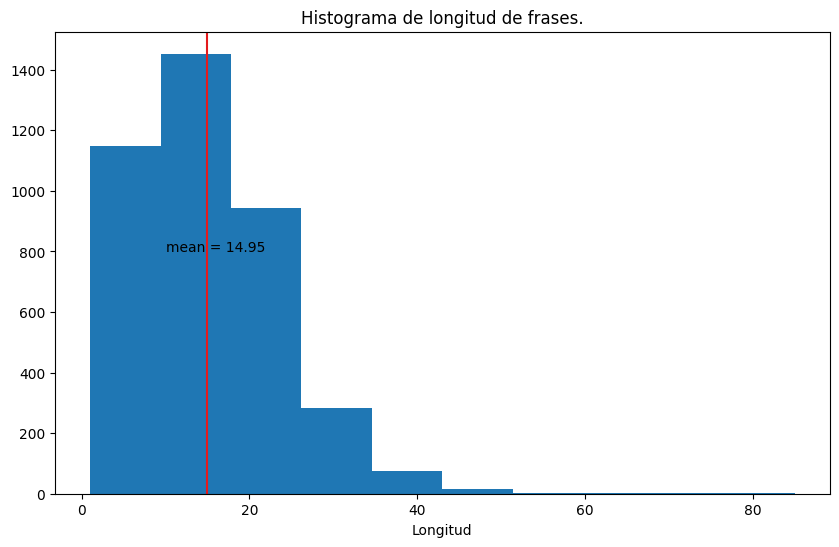
plt.figure(figsize=(10,6))
plt.hist([len(sentence) for sentence in sentences])
plt.axvline(avg_len, color='#e41a1c')
plt.title('Histograma de longitud de frases.')
plt.xlabel('Longitud')
plt.text(10, 800, 'mean = %.2f' % avg_len)
plt.show()
13.4. Looking for Similarity#
With the database we have, we generate representation vectors for each word. In this way, we can find the similarity between words or phrases.
# Treinamos Word2Vec com todos las frases
model = Word2Vec(sentences, workers=3, sg=1, min_count=3, window=10)
word_vectors = model.wv
# Estoy buscando similaridad
# Los 10 mejores
num_best = 10
# Genero con el modelo utilizando las 10mil primeras oraciones
# Con Insantance genero un buscador de similaridad
instance = WmdSimilarity(sentences[:10000], model, num_best=num_best)
# Busco alcalde
# proveedores
text = 'alcalde'
sentence = nltk.word_tokenize(text.lower(), language='spanish')
print(sentence)
query = preprocessing(sentence)
print(query)
sims = instance[query] # A query observa na classe de similaridade.
['alcalde']
['alcalde']
# Mostramos los resultados de la pregunta
print('Query:')
print(text)
for i in range(num_best):
print("")
print('sim = %.4f' % sims[i][1])
print(" ".join(sentences[sims[i][0]]))
Query:
alcalde
sim = 0.8569
prioridades alcalde culpe oposición
sim = 0.8308
horas mérida rueda prensa presidente grupo socialista guillermo fernández vara asamblea
sim = 0.8186
hemeroteca sede santa maría rábida
sim = 0.8103
psoe condena euforia pp
sim = 0.8085
horas toledo vicepresidente grupo parlamentario socialista santiago moreno ofrece rueda prensa cortes
sim = 0.8069
horas guadalajara portavoz grupo municipal socialista magndalena valerio ofrece rueda prensa ayuntamiento
sim = 0.8048
juan ignacio luca tena
sim = 0.8034
style center fernández relevará
sim = 0.8032
horas cáceres comienza pleno diputación cáceres
sim = 0.8029
sede provincial psoe
model.wv.most_similar('proveedores')
[('facturas', 0.9964778423309326),
('pendientes', 0.9962916374206543),
('pago', 0.9947641491889954),
('deudas', 0.980039119720459),
('total', 0.9785211086273193),
('pagos', 0.9784457087516785),
('importe', 0.9756489396095276),
('entidades', 0.9752794504165649),
('locales', 0.9667881727218628),
('pagar', 0.9667481184005737)]
13.5. Retraining NLP models (fine-tuning)#
Large companies and research centers have already generated pre-trained models with large database loads for classification, question and answer models, etc.
In this case we will use BERT (Google AI Language) a pre-trained model that I understand the context of the language. This model needs to be fine-tuned, that is, retrained for a specific task we want to perform. In this case, we want to classify news if they are relevant or not. For this we need a database already labeled, news that we have previously identified whether they are relevant or not. And we will adjust the Bert model for the task we want to perform.
#install the required libraries
!pip install transformers
!pip install datasets
!pip install pandas
!pip install scikit-learn
Show code cell output
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: transformers in /usr/local/lib/python3.9/dist-packages (4.27.4)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.9/dist-packages (from transformers) (6.0)
Requirement already satisfied: huggingface-hub<1.0,>=0.11.0 in /usr/local/lib/python3.9/dist-packages (from transformers) (0.13.3)
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.9/dist-packages (from transformers) (4.65.0)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.9/dist-packages (from transformers) (23.0)
Requirement already satisfied: filelock in /usr/local/lib/python3.9/dist-packages (from transformers) (3.10.7)
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.9/dist-packages (from transformers) (1.22.4)
Requirement already satisfied: tokenizers!=0.11.3,<0.14,>=0.11.1 in /usr/local/lib/python3.9/dist-packages (from transformers) (0.13.2)
Requirement already satisfied: requests in /usr/local/lib/python3.9/dist-packages (from transformers) (2.27.1)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.9/dist-packages (from transformers) (2022.10.31)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.9/dist-packages (from huggingface-hub<1.0,>=0.11.0->transformers) (4.5.0)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.9/dist-packages (from requests->transformers) (2.0.12)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.9/dist-packages (from requests->transformers) (1.26.15)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.9/dist-packages (from requests->transformers) (3.4)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.9/dist-packages (from requests->transformers) (2022.12.7)
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting datasets
Downloading datasets-2.11.0-py3-none-any.whl (468 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 468.7/468.7 KB 15.5 MB/s eta 0:00:00
?25hRequirement already satisfied: requests>=2.19.0 in /usr/local/lib/python3.9/dist-packages (from datasets) (2.27.1)
Collecting xxhash
Downloading xxhash-3.2.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (212 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 212.2/212.2 KB 27.6 MB/s eta 0:00:00
?25hCollecting aiohttp
Downloading aiohttp-3.8.4-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.0/1.0 MB 41.2 MB/s eta 0:00:00
?25hRequirement already satisfied: tqdm>=4.62.1 in /usr/local/lib/python3.9/dist-packages (from datasets) (4.65.0)
Requirement already satisfied: fsspec[http]>=2021.11.1 in /usr/local/lib/python3.9/dist-packages (from datasets) (2023.3.0)
Requirement already satisfied: packaging in /usr/local/lib/python3.9/dist-packages (from datasets) (23.0)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.9/dist-packages (from datasets) (6.0)
Collecting responses<0.19
Downloading responses-0.18.0-py3-none-any.whl (38 kB)
Requirement already satisfied: pandas in /usr/local/lib/python3.9/dist-packages (from datasets) (1.4.4)
Collecting multiprocess
Downloading multiprocess-0.70.14-py39-none-any.whl (132 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 132.9/132.9 KB 18.6 MB/s eta 0:00:00
?25hRequirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.9/dist-packages (from datasets) (1.22.4)
Requirement already satisfied: pyarrow>=8.0.0 in /usr/local/lib/python3.9/dist-packages (from datasets) (9.0.0)
Requirement already satisfied: huggingface-hub<1.0.0,>=0.11.0 in /usr/local/lib/python3.9/dist-packages (from datasets) (0.13.3)
Collecting dill<0.3.7,>=0.3.0
Downloading dill-0.3.6-py3-none-any.whl (110 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 110.5/110.5 KB 15.6 MB/s eta 0:00:00
?25hCollecting multidict<7.0,>=4.5
Downloading multidict-6.0.4-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (114 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 114.2/114.2 KB 16.5 MB/s eta 0:00:00
?25hRequirement already satisfied: attrs>=17.3.0 in /usr/local/lib/python3.9/dist-packages (from aiohttp->datasets) (22.2.0)
Collecting yarl<2.0,>=1.0
Downloading yarl-1.8.2-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (264 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 264.6/264.6 KB 28.7 MB/s eta 0:00:00
?25hCollecting aiosignal>=1.1.2
Downloading aiosignal-1.3.1-py3-none-any.whl (7.6 kB)
Collecting async-timeout<5.0,>=4.0.0a3
Downloading async_timeout-4.0.2-py3-none-any.whl (5.8 kB)
Collecting frozenlist>=1.1.1
Downloading frozenlist-1.3.3-cp39-cp39-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl (158 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 158.8/158.8 KB 21.5 MB/s eta 0:00:00
?25hRequirement already satisfied: charset-normalizer<4.0,>=2.0 in /usr/local/lib/python3.9/dist-packages (from aiohttp->datasets) (2.0.12)
Requirement already satisfied: filelock in /usr/local/lib/python3.9/dist-packages (from huggingface-hub<1.0.0,>=0.11.0->datasets) (3.10.7)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.9/dist-packages (from huggingface-hub<1.0.0,>=0.11.0->datasets) (4.5.0)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.9/dist-packages (from requests>=2.19.0->datasets) (2022.12.7)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.9/dist-packages (from requests>=2.19.0->datasets) (3.4)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.9/dist-packages (from requests>=2.19.0->datasets) (1.26.15)
Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.9/dist-packages (from pandas->datasets) (2022.7.1)
Requirement already satisfied: python-dateutil>=2.8.1 in /usr/local/lib/python3.9/dist-packages (from pandas->datasets) (2.8.2)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.9/dist-packages (from python-dateutil>=2.8.1->pandas->datasets) (1.16.0)
Installing collected packages: xxhash, multidict, frozenlist, dill, async-timeout, yarl, responses, multiprocess, aiosignal, aiohttp, datasets
Successfully installed aiohttp-3.8.4 aiosignal-1.3.1 async-timeout-4.0.2 datasets-2.11.0 dill-0.3.6 frozenlist-1.3.3 multidict-6.0.4 multiprocess-0.70.14 responses-0.18.0 xxhash-3.2.0 yarl-1.8.2
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: pandas in /usr/local/lib/python3.9/dist-packages (1.4.4)
Requirement already satisfied: python-dateutil>=2.8.1 in /usr/local/lib/python3.9/dist-packages (from pandas) (2.8.2)
Requirement already satisfied: numpy>=1.18.5 in /usr/local/lib/python3.9/dist-packages (from pandas) (1.22.4)
Requirement already satisfied: pytz>=2020.1 in /usr/local/lib/python3.9/dist-packages (from pandas) (2022.7.1)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.9/dist-packages (from python-dateutil>=2.8.1->pandas) (1.16.0)
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.9/dist-packages (1.2.2)
Requirement already satisfied: joblib>=1.1.1 in /usr/local/lib/python3.9/dist-packages (from scikit-learn) (1.1.1)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.9/dist-packages (from scikit-learn) (3.1.0)
Requirement already satisfied: scipy>=1.3.2 in /usr/local/lib/python3.9/dist-packages (from scikit-learn) (1.10.1)
Requirement already satisfied: numpy>=1.17.3 in /usr/local/lib/python3.9/dist-packages (from scikit-learn) (1.22.4)
#import what we need later
import datasets
from datasets import load_dataset
from datasets import Dataset, DatasetDict
import pandas as pd
from sklearn.model_selection import train_test_split
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-2-f3d11f56cc2a> in <cell line: 2>()
1 #import what we need later
----> 2 import datasets
3 from datasets import load_dataset
4 from datasets import Dataset, DatasetDict
5
ModuleNotFoundError: No module named 'datasets'
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
---------------------------------------------------------------------------
# Importamos la data
our_data = pd.read_csv("https://www.dropbox.com/s/tbjr8g1hslb8q4o/Full-Economic-News-DFE-839861.csv?dl=1" , encoding = "ISO-8859-1" ) \
.sample( n = 2000 ) \
.reset_index( drop = True )
our_data.shape
(1054, 1)
# Tomamos solamente dos columnas el texto y Y, relevance
# Cambiamos yes y No por 1 y 0
mylen = len(our_data["text"].tolist())
mytexts = [] #will contain the text strings
mylabels = [] #will contain the label as 1 or 0 (Yes or No respectively)
for i in range(0,mylen):
if str(our_data['relevance'][i]) == 'yes':
mytexts.append(str(our_data["text"][i]))
mylabels.append(1)
elif str(our_data["relevance"][i]) == "no":
mytexts.append(str(our_data["text"][i]))
mylabels.append(0)
else:
print("skipping")
len(mytexts)
len(mylabels)
skipping
1999
# Separamos train y test data
# Solo 25% de data para test
train_texts, test_texts, train_labels, test_labels = train_test_split(mytexts, mylabels, test_size=.25)
train_texts, val_texts, train_labels, val_labels = train_test_split(train_texts, train_labels, test_size=0.1)
# Obtenemos el modelo bert
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
# Estemodelo tiene un tokenizador que usaremos para incorporar nuestra
# data
train_encodings = tokenizer(train_texts, truncation=True, padding=True)
val_encodings = tokenizer(val_texts, truncation=True, padding=True)
test_encodings = tokenizer(test_texts, truncation=True, padding=True)
# Introducimos nuestra data al modelo
import torch
class MyDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
# Seleccionamos los encodings. Texto/data
# Labels, Y, lo que queremos predesir
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
# Cada texto lo convertimos en un vector tipo tensor
# De igual manera los labels
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)
# Generamos la dataset para el input
train_dataset = MyDataset(train_encodings, train_labels)
test_dataset = MyDataset(test_encodings, test_labels)
val_dataset = MyDataset(val_encodings, val_labels)
# Tomamos Bert para la clasificación
from transformers import BertForSequenceClassification, Trainer, TrainingArguments
from datasets import load_metric
# Especificamos los argumentos para el re entrenamiento
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs # number of times to change the model
per_device_train_batch_size=16, # batch size per device during training # number of observations
per_device_eval_batch_size=64, # batch size for evaluation # of obs for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
)
# Definimos la metrica para el re entrenamiento
def compute_metrics(eval_preds):
metric = load_metric("accuracy", "f1")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# Tomamos el modelo
model = BertForSequenceClassification.from_pretrained("bert-base-cased")
# Instance del Re entrenamiento del Modelo
trainer = Trainer(
model=model, # the instantiated 🤗 Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=val_dataset, # evaluation dataset
compute_metrics=compute_metrics #specify metrics
)
Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForSequenceClassification: ['cls.predictions.transform.dense.weight', 'cls.seq_relationship.bias', 'cls.predictions.bias', 'cls.seq_relationship.weight', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.weight']
- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
# Entrenando el modelo
trainer.train()
/usr/local/lib/python3.9/dist-packages/transformers/optimization.py:391: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(
| Step | Training Loss |
|---|---|
| 10 | 0.508100 |
| 20 | 0.505600 |
| 30 | 0.553900 |
| 40 | 0.430700 |
| 50 | 0.497200 |
| 60 | 0.464900 |
| 70 | 0.456900 |
| 80 | 0.481600 |
| 90 | 0.497000 |
| 100 | 0.432500 |
| 110 | 0.451200 |
| 120 | 0.493300 |
| 130 | 0.509600 |
| 140 | 0.525000 |
| 150 | 0.451200 |
| 160 | 0.479000 |
| 170 | 0.473200 |
| 180 | 0.423700 |
| 190 | 0.467900 |
| 200 | 0.447600 |
| 210 | 0.405200 |
| 220 | 0.493200 |
| 230 | 0.458900 |
| 240 | 0.431900 |
| 250 | 0.450800 |
TrainOutput(global_step=255, training_loss=0.47049392812392293, metrics={'train_runtime': 95.2231, 'train_samples_per_second': 42.5, 'train_steps_per_second': 2.678, 'total_flos': 1064810441041920.0, 'train_loss': 0.47049392812392293, 'epoch': 3.0})
import numpy as np
# Testeando la predicción del modelo
predictions = trainer.predict(test_dataset)
print(predictions.predictions.shape, predictions.label_ids.shape)
preds = np.argmax(predictions.predictions, axis=-1)
metric =load_metric('accuracy', 'f1')
print(metric.compute(predictions=preds, references=predictions.label_ids))
<ipython-input-33-f345038ad355>:15: FutureWarning: load_metric is deprecated and will be removed in the next major version of datasets. Use 'evaluate.load' instead, from the new library 🤗 Evaluate: https://huggingface.co/docs/evaluate
metric = load_metric("accuracy", "f1")
(500, 2) (500,)
{'accuracy': 0.828}
# Evaluamos el resultado
from sklearn.metrics import confusion_matrix
print(confusion_matrix(predictions.label_ids, preds, labels=[1,0]))
[[ 0 86]
[ 0 414]]